
What is RAG and how can it be used to train LLMs on your own data?
RAG is a one method of fine tuning your LLM.

Retrieval Augmented Generation (RAG) allows LLMs to “augment” their knowledge with data outside the model.
It’s one method for training an LLM to ask questions about your data.
Here’s how it works at a high level:
You store a bunch of your data somewhere in a format that captures meaning and is easily searchable (data processing & storage).
Then your application takes your prompt and it looks for documents matching that query (retrieval).
These matching documents are then passed to the LLM and used in generating a response (generation).
Here’s how it works under the hood:
Data Processing & Storage
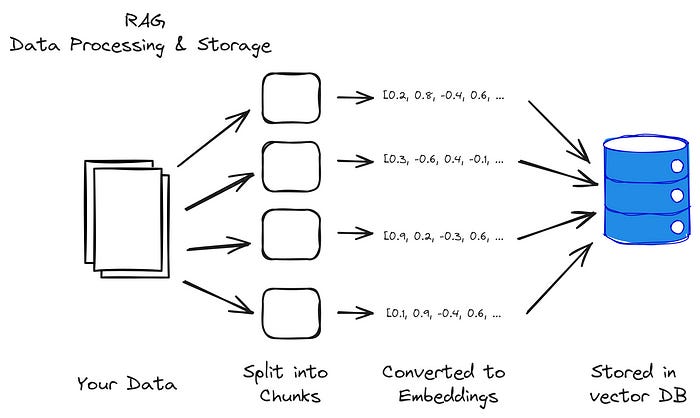
1) Load documents of your data for processing. Any text data works here.
2) Split the documents. There are a variety of methods that can be applied here and will have implications on how well your model performs.
3) Create embeddings. Take the document splits (aka chunks) and convert these text chunks into numbers (aka embeddings). These embeddings attempt to capture the meaning of the text.
4) Embeddings are stored in a vector database.
Retrieval & Generation
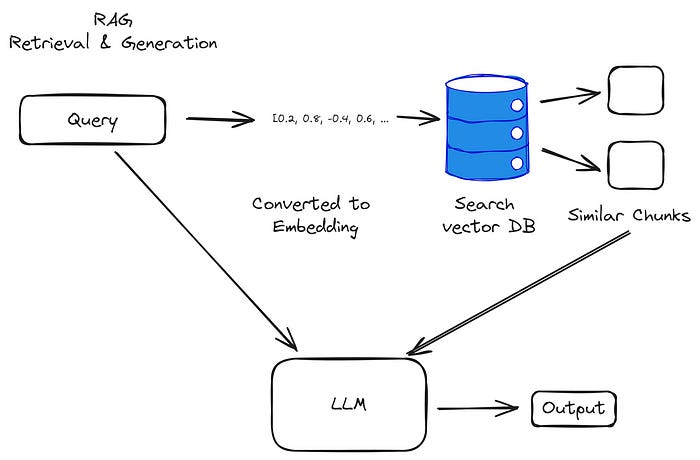
5) Your query is converted into an embedding.
6) Using this embedding you look up similar embeddings in the vector database to find the most relevant chunks you’ve stored.
7) The retrieved chunks and the original query are passed into the LLM.
8) The LLM generates your output and can cite what data it used.
Why this is cool:
If you have a repository of text data, a simple RAG application can help you get more use out of LLMs.
No it’s not magic, but with the proper tuning during this process, it can be valuable and save time.
Some context:
RAG is only one method for “tuning an AI” to work with your data.
Like everything in engineering, your use case and what trade offs you’d like to accept will determine the best approach to take.
Next steps:
PrivateGPT is a all-in one app you can run locally to run an LLM on your own data. Just setup your environment and add your documents.
LangChain is framework for buillding LLM apps in Python. It has all the pieces you need to build your own RAG application on your data.
Deeplearning.ai by Andrew Ng has a whole bunch of free courses on building LLM applications. Two I did recently were: