
How do time series foundation models create embeddings
Embeddings help Transformer models understand your time series

Before an AI model can learn from your data, you need to translate the data into a language the model can interpret.
These are the embeddings and it’s the first step in training a model.
Without embeddings your model won’t recognize meaningful patterns in the data.
What is an embedding?
Embeddings are a numerical representation of your data that captures as much meaning as possible.
Raw time series data is only a sequence of numbers, but an embedding transforms these numbers into a rich, multi-dimensional representation that captures patterns and relationships.
Imagine trying to describe a market trend. You wouldn't just say "the price went up" - you'd describe the speed of the rise, the volume patterns, support & resistance levels, and how it compares to historical movements.
Similarly, an embedding captures multiple dimensions of a time series pattern beyond just the raw values.
What is a time series patch?
Modern time series models like PatchTST don't embed individual time points. Instead, they use "patches" - segments of consecutive time steps treated as a single unit.
It's like reading a book: rather than focusing on individual letters, you process entire words or phrases at once to understand meaning. Similar to how Large Language Models treat groups of letters as tokens.
A patch might contain 16-32 consecutive time steps. The right patch size for your use case is an open area of research.
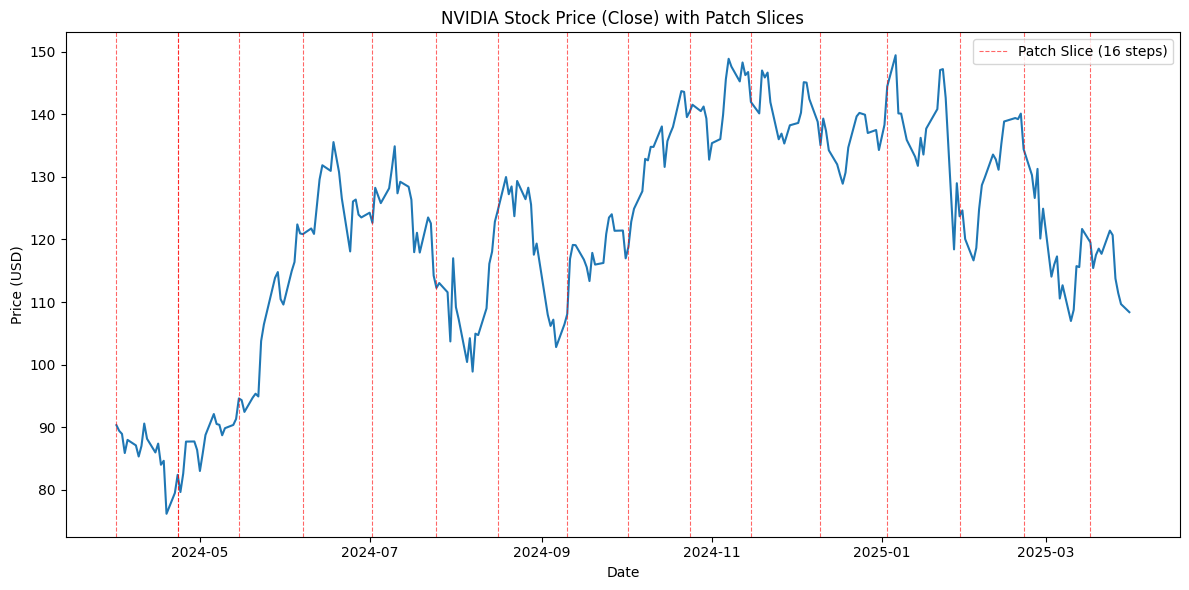
Here’s what patches would look like
Given a year of NVDA closing prices, we would slice it into patches of 16 time steps (16 trading days).
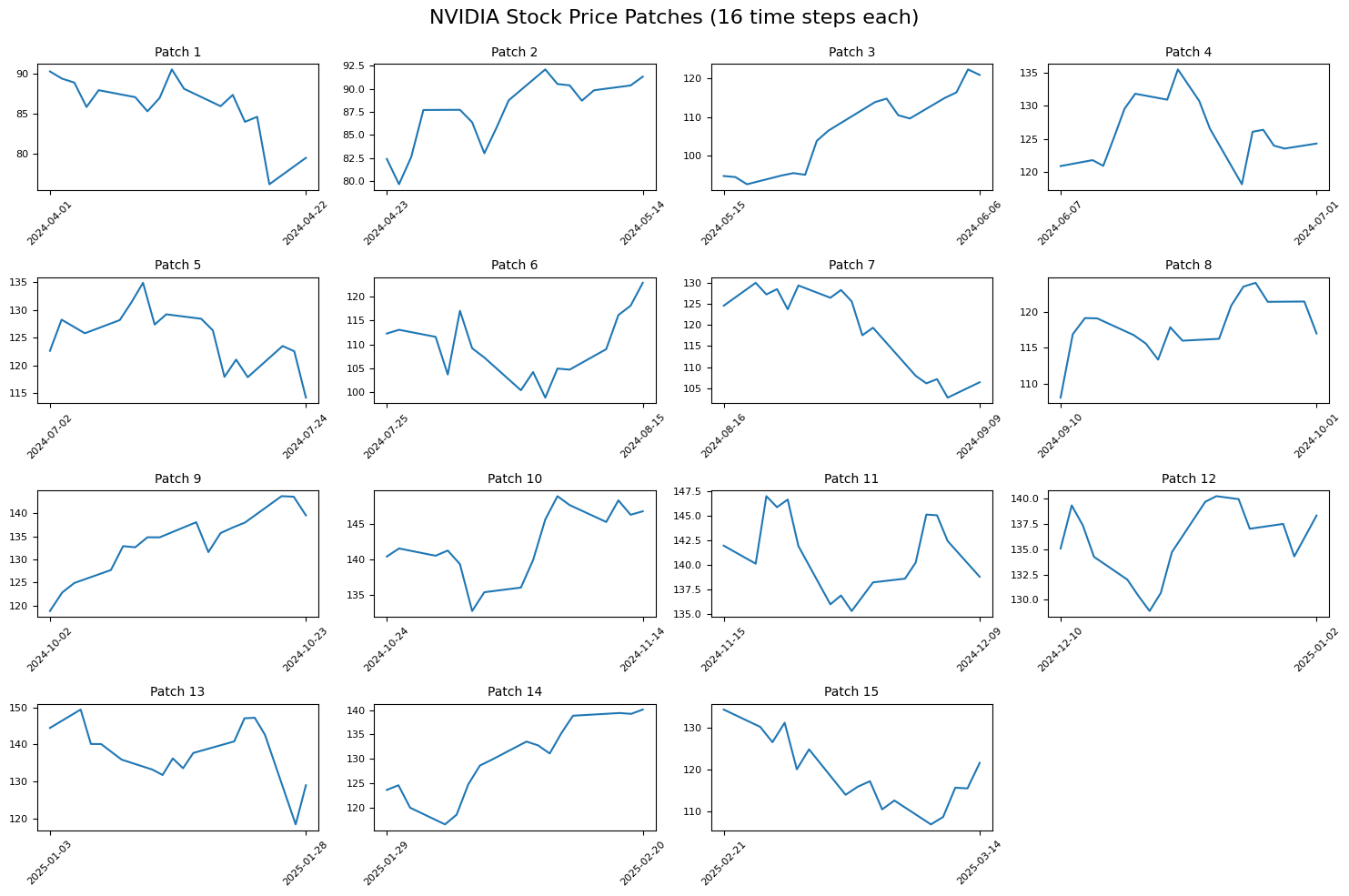
Each one of these result slices results in a single patch that would be embedded and treated as an individual token to our model.
The embedding process
To create the embeddings we take the raw time series data and “project” it into a higher dimensional space.
Projecting it just means we do some matrix multiplication between our raw values and a set of weights that is initially random but our model learns to adjust through training.
The process looks like this:
Take a patch of time steps (e.g., 16 consecutive values)
Multiply by a weight matrix (learned during training, initially random)
Transform into a higher-dimensional representation (e.g., 512 dimensions)
# Simple example of patch embedding
def create_patches(time_series, patch_size=16):
patches = []
for i in range(0, len(time_series) - patch_size + 1):
patch = time_series[i:i+patch_size]
patches.append(patch)
return np.array(patches)
# Linear projection to create embedding
def embed_patches(patches, embedding_dim=512):
# Initialize random weights (these will be learned during training)
weight_matrix = np.random.randn(patches.shape[1], embedding_dim)
# Project patches to embedding space
embeddings = patches @ weight_matrix # Matrix multiplication
return embeddingsThe resulting embeddings live in a "latent space" - a high-dimensional space where similar patterns are mapped close together.
This space isn't directly interpretable by humans, but it allows the model to effectively reason about relationships between different patterns in your data. The “extra” dimensions give the model more room to learn different features or ways to capture patterns in the data.
The First 5 Dimensions of our Embeddings for each Time Patch
dim_1 dim_2 dim_3 dim_4 dim_5
time_1 0.496714 -0.138264 0.647689 1.523030 -0.234153
time_2 1.266911 -0.707669 0.443819 0.774634 -0.926930
time_3 -0.238948 -0.907564 -0.576771 0.755391 0.500917
time_4 -0.626967 1.812449 0.707752 -0.562467 0.632408
time_5 1.727543 0.436324 0.038003 0.120031 0.613518
time_6 0.133541 -0.152470 0.708109 0.956702 -0.785989
time_7 0.513600 -0.532701 -1.169917 -2.872262 -0.027515
time_8 -0.160133 0.671340 0.213197 -0.751969 -0.319054
time_9 -0.327895 0.155191 0.825098 -0.867130 -0.658116
time_10 1.995667 3.109919 0.606723 -0.183197 0.534506
time_11 -1.013896 0.085687 -0.925425 0.255384 -0.895346
time_12 0.482067 0.368733 0.393797 -1.927673 -0.278883
time_13 0.202329 1.631857 -0.733033 1.818062 0.775155
time_14 -1.092164 0.834751 0.913772 -1.545730 1.589839
time_15 0.071254 -1.293508 -0.695695 -0.918127 1.239584
time_16 -0.614323 -0.709789 0.978890 -1.371743 1.608781Importantly, the weights that define this transformation aren't fixed. These start random and are learned during training, gradually organizing the latent space to capture meaningful patterns relevant to the forecasting task.
The beauty of this approach is that the model learns to create useful representations directly from the data. You just provide the data and the compute for the model to do so.
Other embedding approaches
While linear projection is the most common approach today, there are other embedding techniques for time series:
Autoencoder embeddings: Using neural networks to learn compressed representations of time series through encoding and decoding
Time2Vec embeddings: Specialized embeddings that explicitly capture periodicity and seasonality in time series
Time-delay embeddings: Leveraging chaos theory to reconstruct the underlying dynamics of a system
Multi-scale embeddings: Capturing patterns at different time resolutions simultaneously
My research questions
I had many questions about how embeddings were created. My data engineering and trading background understands the value of the data. It seemed odd to me that more time isn’t being invested in how the data is represented before model training.
Apparently there is quite a bit of on-going research but these are some questions I had:
How does patch size affect model performance? Different patterns might be best captured with different patch sizes.
Could we use OHLC (Open-High-Low-Close) representations to compress information even further without losing important patterns?
What about multi-resolution embeddings that capture patterns at multiple time scales simultaneously (similar to how traders look at daily, weekly, and monthly charts together)?
Should we pre-train embedding layers rather than starting from random weights, similar to how language models use pre-trained word embeddings? Would this help model convergence?
I intend to investigate these questions in future research and experiments - please let me know if these questions are interesting or if you have any sources/work related to them.
View all related code here on my GitHub.